
Real time transient detection pipeline
MeerTRAP will search for fast radio transients in real-time in beam-formed data from the Max-Planck Institut fur Radioastronomie (MPIfR) and MeerTRAP beamformer. Both an incoherent beam and 400 coherent beams will be searched. The incoherent beam will be formed using as many dishes as are available, while coherent beam formation is limited by the available computing power so the coherent beams will be formed from 40 dishes. Real-time fast radio transient detections will be performed using a search pulse search pipeline. This involves searching for pulses at different dispersion measures (DMs), up to a DM of 3000 pc cm−3 .
We are currently working towards building a fully-automated, real-time transient detection pipeline. The pipeline is divided into three main parts:
- Data reception
- Real-time GPU based time-domain search
- Candidate classification
- Transient trigger and voltage capture
- Database storage and data exploration
Data capture
The MeerTRAP system will receive data over a 10-Gb s−1 network link from the beamformer (FBUSE). The data are streamed in the form of SPEAD2 packets over the network. The packets are captured by the MeerTRAP backend by subscribing to the relevant multicast group. Each node will receive data via a single multicast group. Once received, the packets are written to PSRDADA ring buffers in the RAM. The downstream pipeline will then query the ring buffers for further processing.
Single-pulse and periodicity search
We are implementing a real-time single pulse and periodicity search pipeline for MeerTRAP to search for fast radio transients and pulsars. The pipeline is managed by PANDA, which is a generic framework being developed for multi-architecture data processing. The framework can manage resources that are available to optimize the functioning pipeline. The single pulse search pipeline is called Cheetah. It is developed with the aim of creating a highly generic, modular pipeline that can be implemented in any environment. Its modular nature makes it easier to integrate new algorithms for fast transient and pulsar searches without affecting the interfaces.
Candidate classification
The real-time nature and large scale of the project represents a serious challenge in terms of the amount of candidates that will be produced by the data analysis pipeline and how quickly these need to be classified, i.e. within a few seconds. We are currently investigating state of the art machine learning algorithms that will be deployed to identify both single pulse events and promising periodicity candidates.
Transient trigger and voltage capture
Once candidate events are reliably identified by the machine learning classifier, the system will issue triggers as Virtual Observatory events (VOEvents; e.g. 4pisky.org/voevents), first only to internal facilities, such as MeerLICHT and the beamformer, and later to a multitude of external collaborative telescopes. These triggers will be released in real-time. Once triggered, the beamformer system will save raw voltage data for subsequent analysis, such as improved temporal resolution of the event, coherent dedispersion of the signal and much refined localisation of the event.
Database storage and data exploration
At the heart of MeerTRAP’s data analysis system will be an extensive database, which we are currently designing. It will allow us to store both aggregate candidate statistics and individual events after candidate classification, together with other pointing information. This database will provide light curves for the whole surveyed sky area and will allow us to search for unexpected variability on various time-scales. This is important to identify flare stars, RRATs and highly-intermittent pulsars, among others. It will also influence our beam tiling strategy.
Rapid transient localisation
When a fast radio transient is detected in the beam formed data, the raw data (data that has not been beam-formed) will be saved, which means that the spatial information is not lost. The raw data can be correlated and imaged in order to localise the fast radio transient to a precision of a few arcseconds. This means that fast radio transients, particularly fast radio bursts (FRBs), detected with MeerTRAP can be localised to the host galaxy, and possibly to regions within the host galaxy. There are currently no systems for real-time detection and rapid localisation of fast radio transients. Rapid localisation ensures rapid source identification for MeerLICHT observations and potentially to trigger follow-up observations with different observatories. Identifying and following-up the locations of FRBs will help to investigate FRB environments and progenitors.
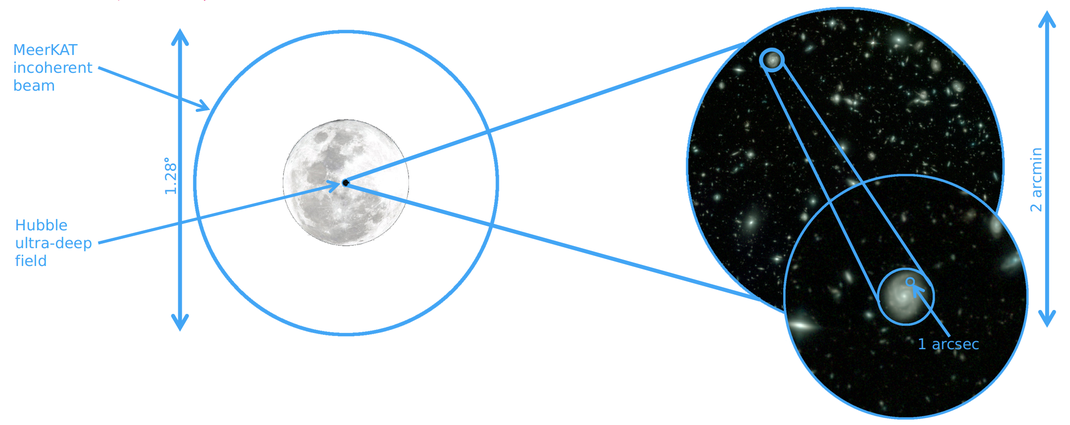
MeerKAT has a large field of view and excellent resolution. Using the incoherent beam to detect an FRB and imaging to localise to arcsecond precision means we can pinpoint which galaxy, and (in some cases) where in the galaxy, an FRB came from.
The first step in the imaging pipeline is correlation. Correlation in radio astronomy is the process by which a power spectrum, the power as a function of frequency, is produced from an array of stations or antennas. Once a power spectrum is obtained it is possible to use inverse Fourier transforms in the spatial domain to produce images. There are two steps in correlation, the Fourier transform or "F" step and the cross-correlation or "X" step. Cross-correlation produces a cross-power spectrum for each pair of antennas in an interferometer, and with enough antennas (and hence many baselines) cross-correlation produces a detailed power-spectrum (cross-correlation products are also known as visibilities or the 2-D Fourier transform of the sky brightness).
Theoretically, cross-correlation assumes that the sky is sampled continuously in time, but real observations are sampled at discrete time-steps and using a finite frequency bandwidth. This means that data needs to be broken into smaller frequency channels in the time-domain via Fourier transforms. The channel width is given by (bandwidth)/(number of frequency channels). However, MeerTRAP observations will already be broken into at least 4096 channels; we only need to perform the X step. To do this we are working on combining the Distributed FX correlator (DiFX) and the xGPU correlator.
Once the data is correlated we need to image the data and localise the fast radio transient. This part of the pipeline is still being investigated. We're looking at CASA clean, WSClean, and difmap for the imaging step. We need to consider the Briggs weighting that we'll use, whether we'll make images using all the baselines, and whether we'll use difference imaging or not.